Complex sentences
During this week we have been studying the type of tokens that make up complex sentences containing more than one verb and how to simplify the sentences entered into the system.
Possible approaches
Mainly two possible solutions have been identified to try to process more complex sentences, composed of more than one verb. The first option would be to simplify the sentences, it is usually intuited that a complex sentence is composed of several clauses so that these clauses could be extracted to form new, simpler and shorter sentences. The other approach is to try to adapt the system to be able to deal with all types of sentences, using templates to extract several triples from the most complex sentences.
We have chosen to follow the first approach as it seems simpler and there are already some proposed solutions to the problem of simplifying complex sentences that can be used or inspired by them. Once the sentences have been simplified, they can be fed into the system already built to generate triples.
Solutions Found
After searching for works related to the problem of simplifying complex sentences three solutions have been found. The first tool can be found here, it seems to be a project based on the standfor parser, after investigating the project report found in the repository it has been seen that the solution seems to work well for sentences with more than two clauses. The methodology followed by the authors consists of three steps: (1) Setting the criteria for a clause, (2) Algorithm for segmentation of clause and (3) Criteria for marking clause boundaries.
The second tool found was published in 2019 and is accompanied by a paper. The methodology presented by the authors consists in first simplifying the sentences by looking at the coordination conjunctions (similar to what was done in coding week 3). The second part consists of separating complex sentences by using subordinating conjunctions (after, because, if, since, etc.)
The last tool can be found in this repository which seems to be the most professional and complete. iSimp, the name of the third solution found, mostly considers coordinations, relative clauses, appositions, parenthesized elements, and introductory phrases to simplify sentences. The following example can be found in its repository:
Active Raf-1 phosphorylates and activates the mitogen-activated protein (MAP) kinase/extracellular signal-regulated kinase kinase 1 (MEK1), which in turn phosphorylates and activates the MAP kinases/extracellular signal regulated kinases, ERK1 and ERK2. (PMID-8557975)
1. Active Raf-2 phosphorylates MEK1
2. MEK1 phosphorylates ERK1
3. MEK1 phosphorylates ERK2
4. Active Raf-2 activates MEK1
5. MEK1 activates ERK1
6. MEK1 activates ERK2
This tool was the only one that could be installed and tested with some of the DBpedia abstracts we are using, here some outputs for a certain sentence:
The former is pursued by historians of the physical sciences, who examine the subject in terms of early chemistry, medicine, and charlatanism, and the philosophical and religious contexts in which these events occurred.
The former is pursued by the philosophical contexts.
The former is pursued by historians of the physical sciences.
The physical sciences who examine the subject in terms of medicine.
The philosophical contexts in which these events occurred.
The religious contexts in which these events occurred.
The physical sciences who examine the subject in terms of early chemistry.
The physical sciences who examine the subject in terms of charlatanism.
The former is pursued by the religious contexts.
All the solutions presented above are based on dependency parse trees using the Stanford parser. Since they use this tool to detect the dependencies, the integration of these solutions in our system is more complicated, we have to download the Stanford models, declare the system variables (classpaths) and in some of them we have to perform other extra steps such as building java or executing some extra scripts. Even if they are not going to be used, we will extract some of the ideas used to build our solution.
Exploring the sentences
In this section we intend to explore complex sentences to understand what tokens you could use to separate them, so that you get several simpler sentences with one verb.
For the sentence The former is pursued by historians of the physical sciences, who examine the subject in terms of early chemistry, medicine, and charlatanism, and the philosophical and religious contexts in which these events occurred. we obtain the following dependency parse tree:
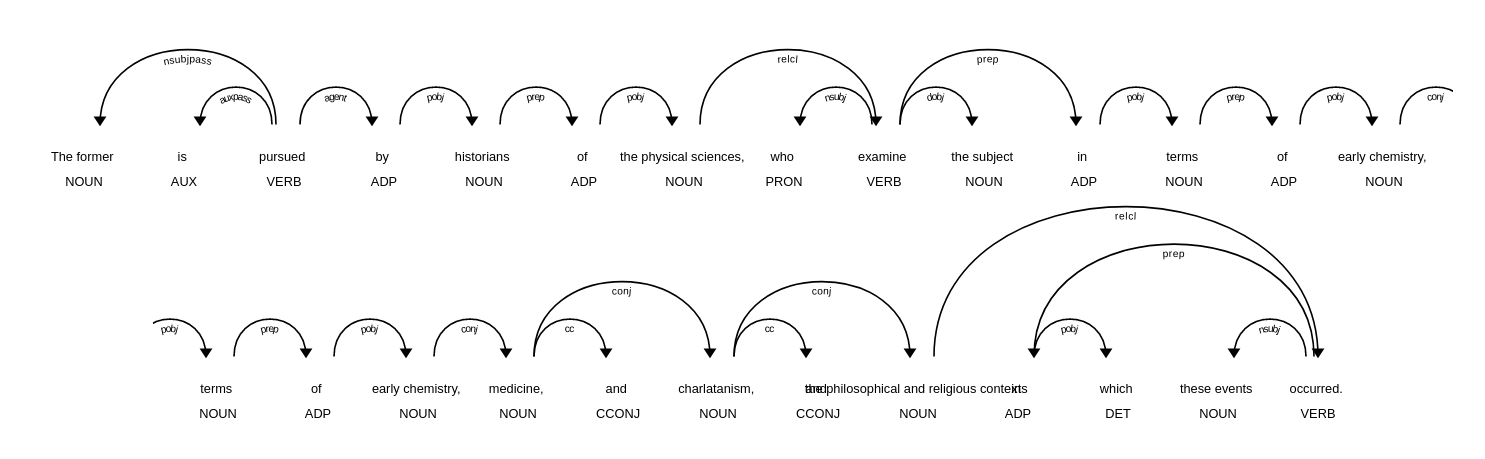
It can be observed that the verbs that are not the root of the dependency parse tree (examine and ocurred) have the token.dep as relcl, which means relative clause.
There are other types of tokens that are associated to the verbs that are not the root of the tree and that we can use to simplify the sentences, for example for the sentence However, they did not abandon the ancients belief that everything is composed of four elements, and they tended to guard their work in secrecy, often making use of cyphers and cryptic symbolism. we obtain the following dependency parse tree:
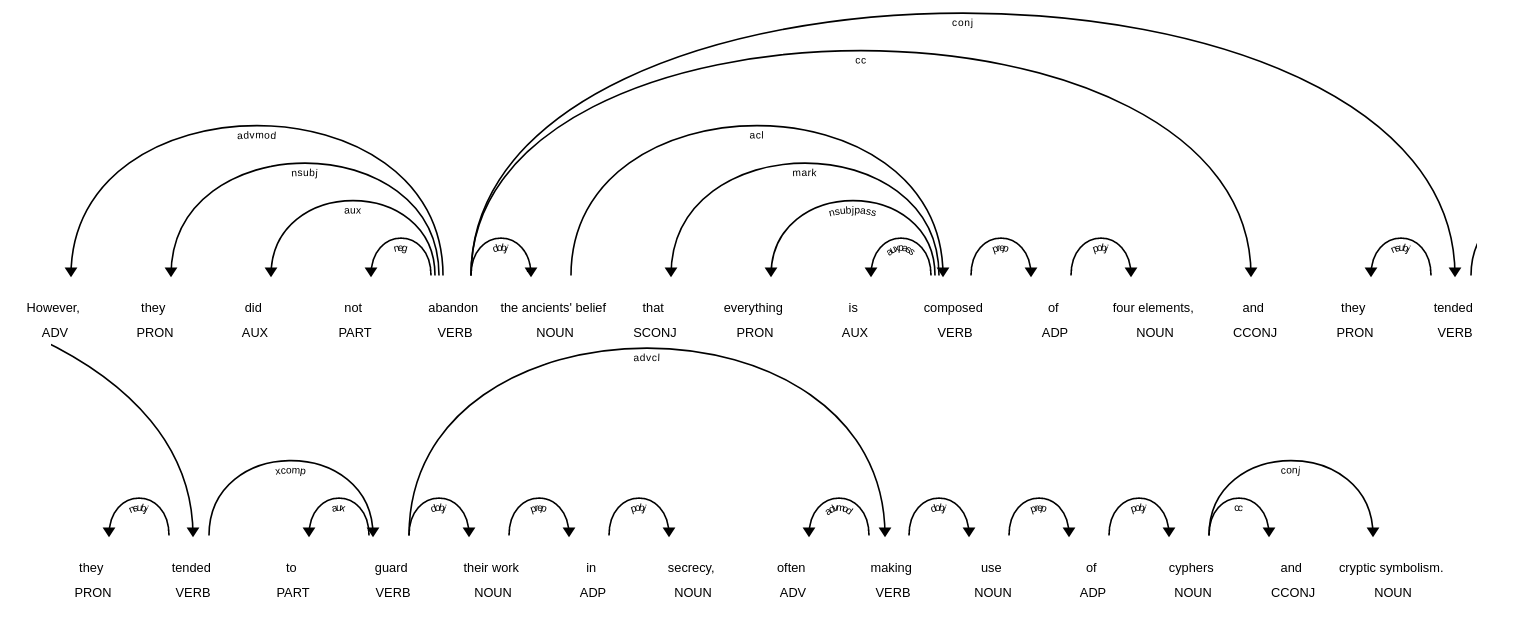
In this case, non-root verbs (composed, tended to guard, making) present token.dep as acl (clausal modifier of noun (adjectival clause)), advcl (adverbial clause) and conj. In addition, we can see that there are sentences with compound verbs that are not aux + verb, these are related to the xcomp dependency and were previously being discarded since sentences with this structure had more than one regular verb.
Proposed solution
If we look at the graphs we can divide the tree into several subtrees if we remove the relations of the tokens representing clause modifiers such as relcl, advcl, acl and cc. For the two sentences introduced above we obtain:
The former is pursued by historians of the physical sciences, who examine the subject in terms of early chemistry, medicine, and charlatanism, and the philosophical and religious contexts in which these events occurred.
1. The former is pursued by historians of the physical sciences ,
2. who examine the subject in terms of early chemistry , medicine , and charlatanism , and the philosophical and religious contexts
3. in which these events occurred
However, they did not abandon the ancients belief that everything is composed of four elements, and they tended to guard their work in secrecy, often making use of cyphers and cryptic symbolism.
1. However , they did not abandon the ancients belief
2. that everything is composed of four elements
3. they tended to guard their work in secrecy
4. often making use of cyphers and cryptic symbolism
To achieve this, the first step is to identify all the tokens that have a modifier clause. Once these tokens are obtained, we explore the subtrees that are generated, being these tokens the root. It is advanced carefully observing if the following token of the subtree is related to another different clause, if this condition is fulfilled the subtree is finished.
This generated sentences can be feed into the previous sistem since they have now one verb or one composed verb (verb+aux or verb+verb)
Other changes
As mentioned above, sentences containing a verb composed of two regular verbs (tend to guard) are now accepted by the system. Previously these were discarded since there were two regular verbs and only simple sentences of a regular verb, auxiliary verb and compound verb (aux+verb) were worked with.
The negations have also been included in the construction of the triplet. For example, in the sentence Mathew did not work yesterday the triplet Mathew | did work | yesterday was produced, which is wrong.
Conclusions
It can be concluded that this week we have identified a way to simplify those more complex sentences into multiple simpler sub-sentences composed of a verb or a compound verb. Although the simple sentences that have been obtained are whole (subject, verb and object), if you cut the tree into subtrees you are losing information that was present thanks to the elements with which they were related in the original sentence. The biggest problem I find in the subjects of the simplified sentences because depending on the case the subject of the new sentence is the subject of the previous one or the predicate of the previous one, for example:
# First example
The former is pursued by historians of the physical sciences
who examine the subject in terms of early chemistry , medicine , and charlatanism , and the philosophical and religious contexts
# In this case who corresponds to --> historians of the physical sciences (obj)
# Second example
However , they did not abandon the ancients belief
that everything is composed of four elements
# In this case everything is the subj (nsubjpass) but does not have sense to replace it for any of the elements of the related sentence
# Third example
they tended to guard their work in secrecy
often making use of cyphers and cryptic symbolism
# In this case the second sentence does not even have a subj so it should use the subj of the related sentence
# --> they often making use ...
On the other hand, I am looking into ways to transform verbs into properties in RDF format, for example the verb works on should be transformed into https://dbpedia.org/ontology/occupation. My tutor mentioned the use of lexicalization, it is still under study.
For more information please check the repository or the source file of this coding week 4.