Building the lexicalization lookup table
This week we have focused on the construction of the lookup table that will allow us to apply lexicalization to infer the property (predicate) of the ontology from the verb + preposition of a sentence. As we did when developing the pipeline to process the sentences, we will only use simple sentences with verbs.
Length and structure of the lexicalization table
Once we have understood the process to transform the predicates into properties of the DBpedia ontology, we need to consider which verbs and prepositions we are going to take into account. Obviously we cannot take into account all the combinations since it would take too much time to develop the table.
To get an idea of which verbs and which prepositions to consider, we have taken a sample of 10,000 DBpedia abstracts and extracted the verbs and prepositions that appear in simple sentences (with only one verb). The results can be seen in the following directory. For each type of sentence, the most frequent verbs, prepositions and verbs + prepositions have been calculated.
For example, these are the ten most common verbs in simple sentences:
"be": 7655,
"have": 482,
"play": 313,
"locate": 281,
"serve": 256,
"include": 248,
"win": 243,
"release": 238,
"hold": 212,
"find": 211,
As can be seen, the verb to be appears in most of the sentences taken in the sample and there is a big difference between this verb and the second most common verb have. The case of the verb to be will be explained in more detail in the next section of this blog post, since this verb should always be interpreted as the rdf:type property.
Once these lists were constructed, the cumulative sum of the number of occurrences was calculated, in this way we can see how many cases we covered with each sublist of verbs. In the following plot you can see the verbs in the x-axis and the the percentage of cases covered from the X to the origin (cumulative sum) in the y-axis. 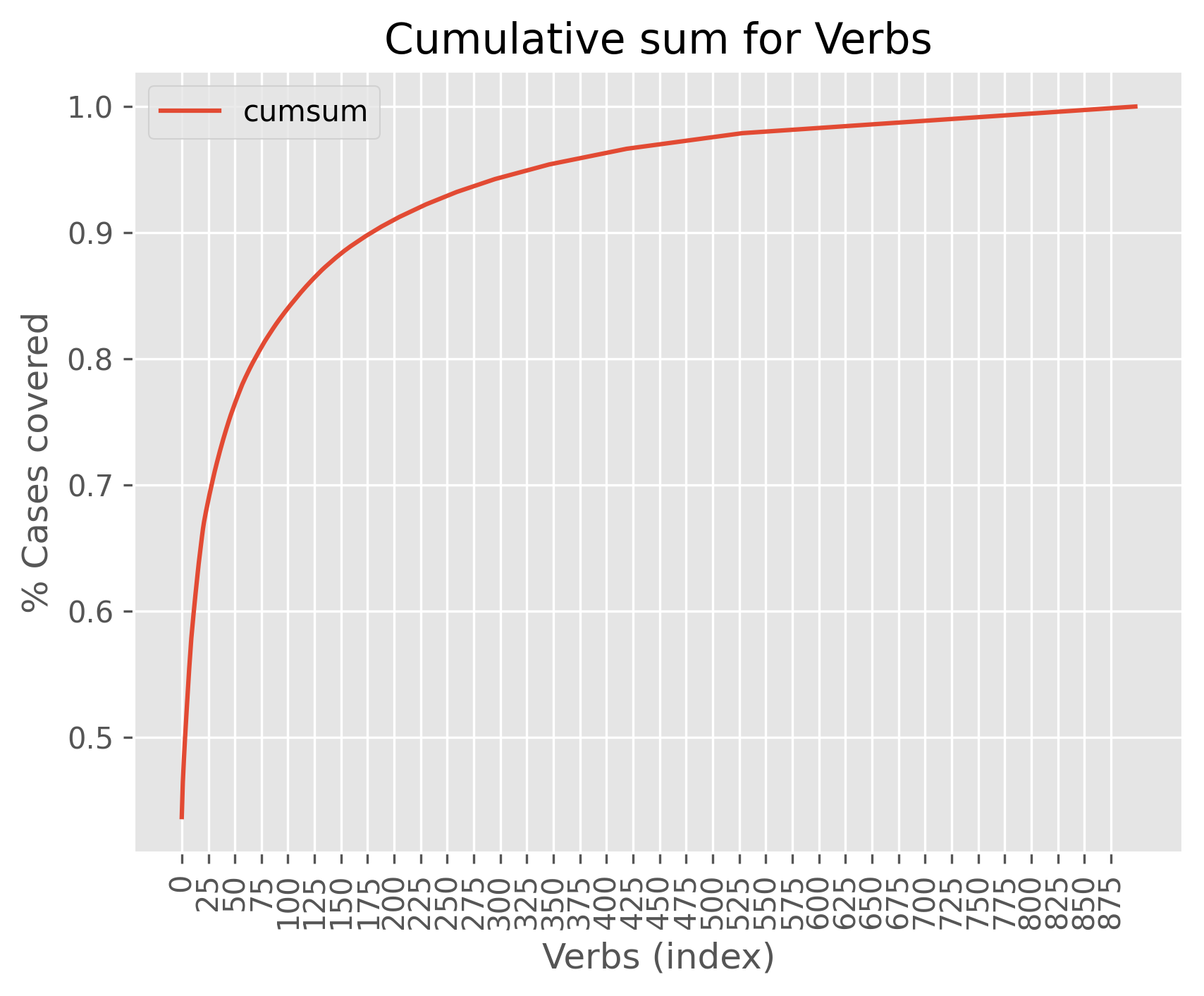
Each time more verbs are added (X-axis) the difference of cases covered becomes smaller. For example, if we wanted to cover 90% of the cases we would have to include 175 verbs in the lexicalization table, which is a huge manual workload that is a bit out of the scope of this project. For the moment only the first 30 verbs will be included, giving a coverage of 70% of the cases.
In the case of prepositions, the following plot has been obtained:
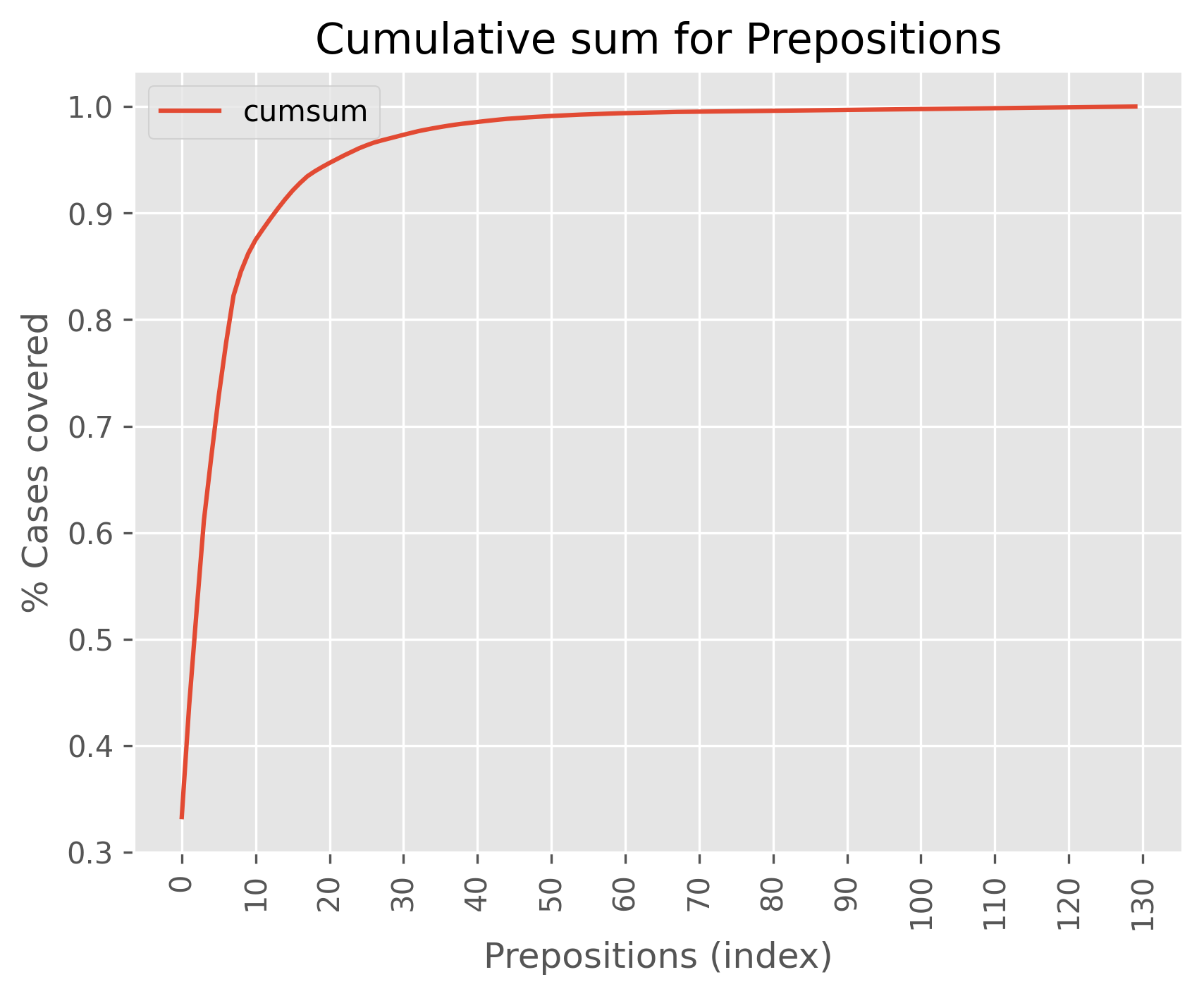
Prepositions present a behavior similar to that of verbs, the more we consider the smaller the difference in the number of cases covered. However, in this case, taking into account only 10 prepositions covers 90% of the cases in the sample taken.
If we choose 30 verbs and 10 prepositions, we have to associate 300 different combinations with their corresponding properties, which is quite a lot of manual work. Between this week and the next weeks the lexicalization table will be filled in.
These plots have been obtained from the following python script
With the selected verbs and prepositions, the lexicalization table is built, which after all is a dictionary where the key is the verb and the value of each verb is a dictionary with the possible prepositions, for example:
{
"be": {
"in": "UNK",
"as": "UNK",
"on": "UNK",
"to": "UNK",
"at": "UNK",
"for": "UNK",
"DEF": "UNK"
},
"have": {
"in": "UNK",
"as": "UNK",
"on": "UNK",
"to": "UNK",
"at": "UNK",
"for": "UNK",
"DEF": "UNK"
}
...
}
In the previous example only some of the selected verbs and prepositions have been shown, to see the complete table go to next file.
In addition to the selected prepositions we have added a DEF token that will be used when the verb to be translated does not have any preposition or the preposition does not appear in the list.
In the example, the values for each preposition are initialized to UNK, which means that you have no information about the verb + preposition combination. If this is the case, you will have to look at the value of DEF or discard the triple.
To build the table structure we have made use of the script build_lookup_table.py.
Content of the lexicalization table
With the structure of the table now it only remains to fill the values of each verb + preposition combination with the corresponding property, for example for the combination work as the table is expected to return https://dbpedia.org/ontology/occupation.
Although these translations seem simple, there are several problems. The first one is that for a verb + preposition there can be several lexicalizations, for example for the combination move to the lexicalization could be https://dbpedia.org/ontology/country, https://dbpedia.org/ontology/city or another one that refers to a location. Faced with this problem what has been decided to do is, for each combination not to put only one value but to write down a list of possible lexicalizations. When translating the verb+preposition into a property we will go through the list of possible lexicalizations and we will check which property best fits the triple by checking that the range and domain of the property corresponds to the type of resource in the subject and object. For example in the case Obama moves to Spain we would get https://dbpedia.org/page/Barack_Obamahttps://dbpedia.org/ontology/countryhttps://dbpedia.org/page/Spain , however if the phrase was Obama moves to Madrid we would get https://dbpedia.org/page/Barack_Obamahttps://dbpedia.org/ontology/city``https://dbpedia.org/page/Madrid`. TThis will be implemented in the next week, for now we will select one from the list (if there are several properties for a given combination).
The other problem identified is to correctly choose which properties correspond to each combination of verb and preposition. First, there are 3 main types of properties: datatype, functional and object. Since the first two types of properties relate entities to literals we will only use Object properties.
The latest version of the DBpedia ontology (2021.08.06) contains 1156 ObjectProperties, the problem is to know for sure which properties cover each combination of verb and preposition. Since I do not have so much experience with the ontology and I have not found any online resource to help me to make these conversions, I have downloaded all the properties in a list and I have been searching in the file (cntrl+f) for the properties.
Since I have not created a new script to obtain the properties, the following are the main code lines to extract this type of elements from the DBpedia graph:
from rdflib import Graph, OWL
props = []
for s, p, o in g.triples((None, None, OWL.ObjectProperty)):
props.append(s)
The list of properties can be found here. In addition, DBlexipedia has also been used to complete the lexicalization table.
The final lexicalization table can be seen here.
The case of the verb To be
The case of the verb to be is different from the rest of verbs, because this verb when it goes without any preposition corresponds to rdf:type. The main problem of processing this pattern is that it is the only one with the resource property class pattern, so we have to extract from the object of the phrase a class of the DBpedia ontology instead of a resource using DBpedia spotlight.
For the moment we have come up with two alternatives, the first would be to use a lexicalization table with synonyms for each DBpedia class, when querying the table with a synonym of a class should return the class. On the other hand, there is the case of calculating the similarity between the object and each of the classes in the ontology and retrieve the class most similar to the object of the phrase.
At the moment, the pipeline will not treat the case to be differently from the other verbs, producing resource rdf:type resource, which is wrong. This problem will be fixed during the next week.
Conclusions
In conclusion, during this week we have been able to see which verbs and prepositions are the most common and how we can convert these combinations into properties of the DBpedia ontology. The creation of the lexicalization table has been quite complicated since I don’t have enough experience with this ontology to determine which properties correspond to each combination of verb and preposition. It is possible that in the next weeks some modifications will be made to this approach or more verbs will be added.
In the following week we will focus on making some tweaks to the pipeline and creating tests to evaluate the performance of the application and identify cases where it does not produce good results. During week 9 we will build the web/command line application and in the last week we will focus on producing documentation, benchmarks, bug fixes and final tweaks.
For more information please check the repository or the source file of this coding week 7.