Web application demo
In the last week I have dedicated myself mainly to the creation of a web application to demonstrate the operation of the pipeline developed during the last 9 weeks. In addition, it is intended to create an alternative that works via command line.
Web framework
The first step in the creation of a web application is to choose which tool or framework best suits our development. Based on the python language there are many frameworks such as flask, django, pyramid or bottle among others.
Initially we had the idea of building the application using Flask as it is a very simple and lightweight framework. After several days testing this tool and trying to build the web application i was struggling with some parts of this framework, mainly with the frontend part since i have not a lot of experience with html+css (bootstrap).
Looking for alternatives I found another tool to generate web pages very similar to Shiny (from R). It is streamlit, an open-source framework that is intended to build web applications for Machine Learning and Data Science. This framework allows you to write an app the same way you write a python code, making it seamless to work on the interactive loop of coding and viewing results in the web app.
To install this tool just run the following command: pip3 install streamlit.
Web App
The basic operation of the web application is that the user enters a text as input and a ttl file is generated with the generated RDF triples. Apart from this main function we have included some interactive elements so that the user can customize how the triples are processed or what kind of outputs will be shown on the screen.
Using the default streamlit theme we have managed to build the following user interface:
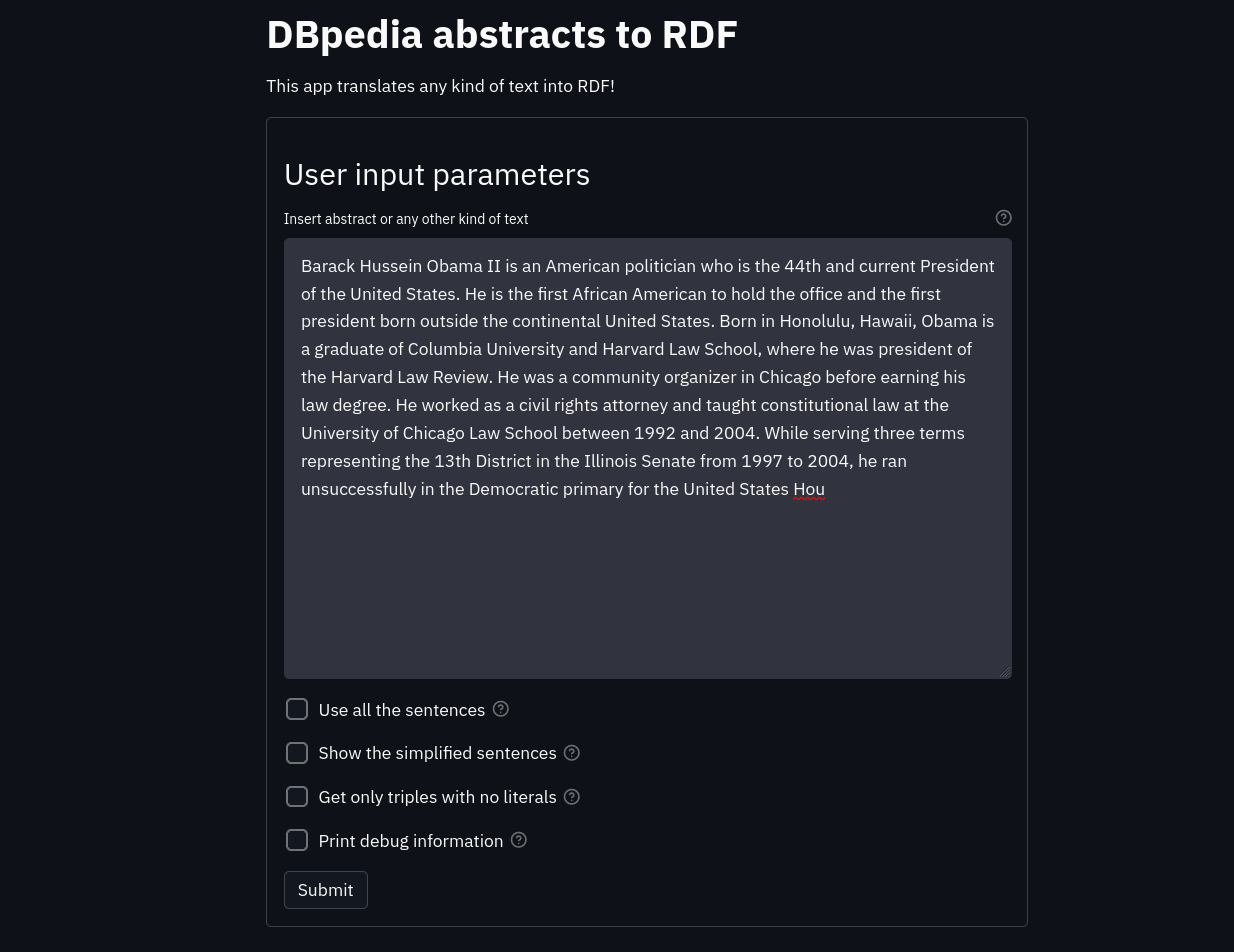
As can be seen in the image, the main graphical component is the text area where the user enters a text (for example an abstract from a DBpedia page). In addition, there are four check boxes:
-
use all sentences: if true all sentences will be used to generate triples (not only simple sentences), users are advised to leave this option unchecked as the quality of triples for complex sentences is worse than triples for simple sentences.
-
Show simplified sentences: If true the text triples will be printed on the web page as extra output.
-
Get only the triples without literals: If true only the triples that have no errors in the structure will be selected, those triples that follow the pattern
resource | property | resource. -
Print debugging information: If true, each sentence will be printed at the end of the web page with the triples generated from it.
The following two images show the output of RDF triples, text triples (simplified statements) and debug information:
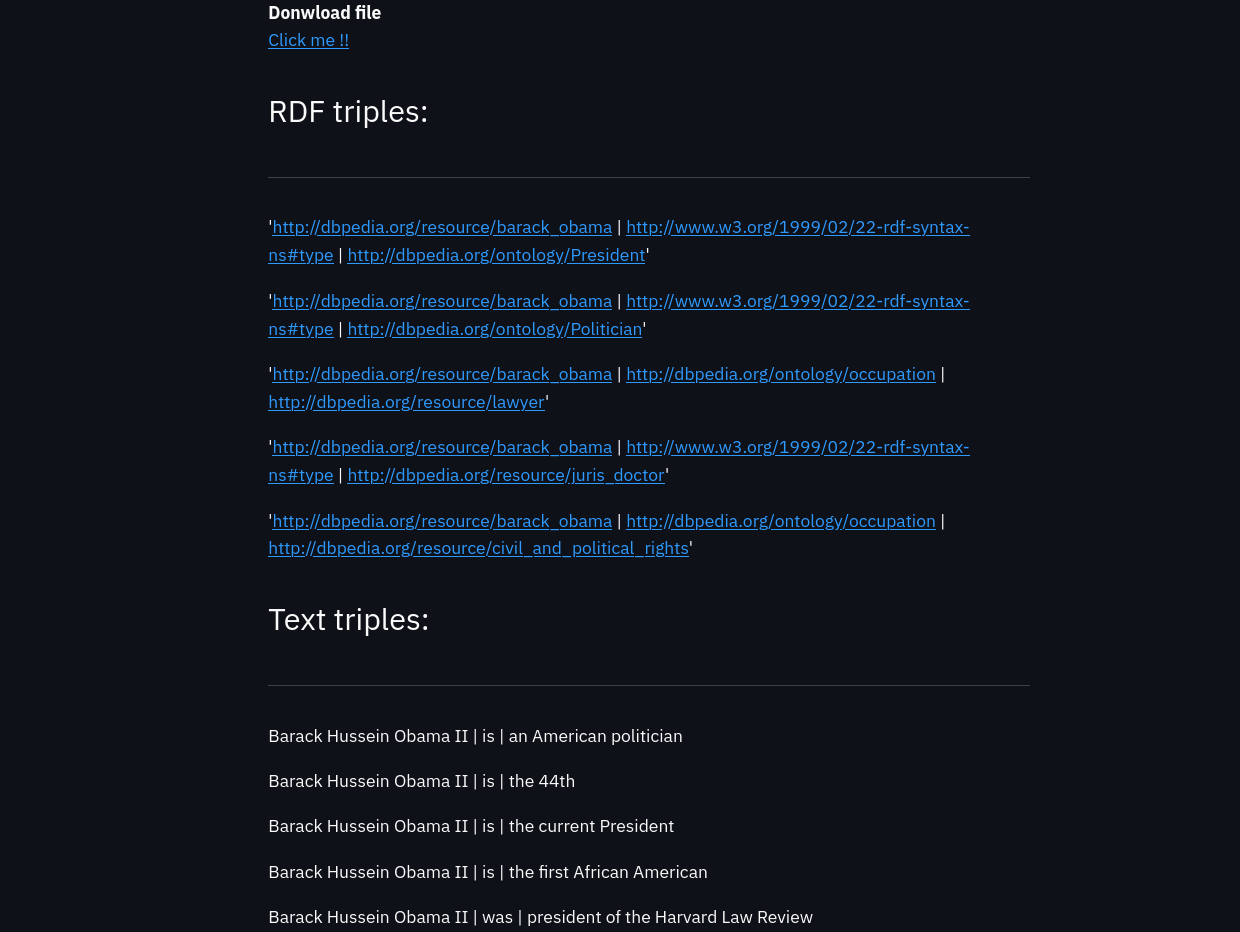
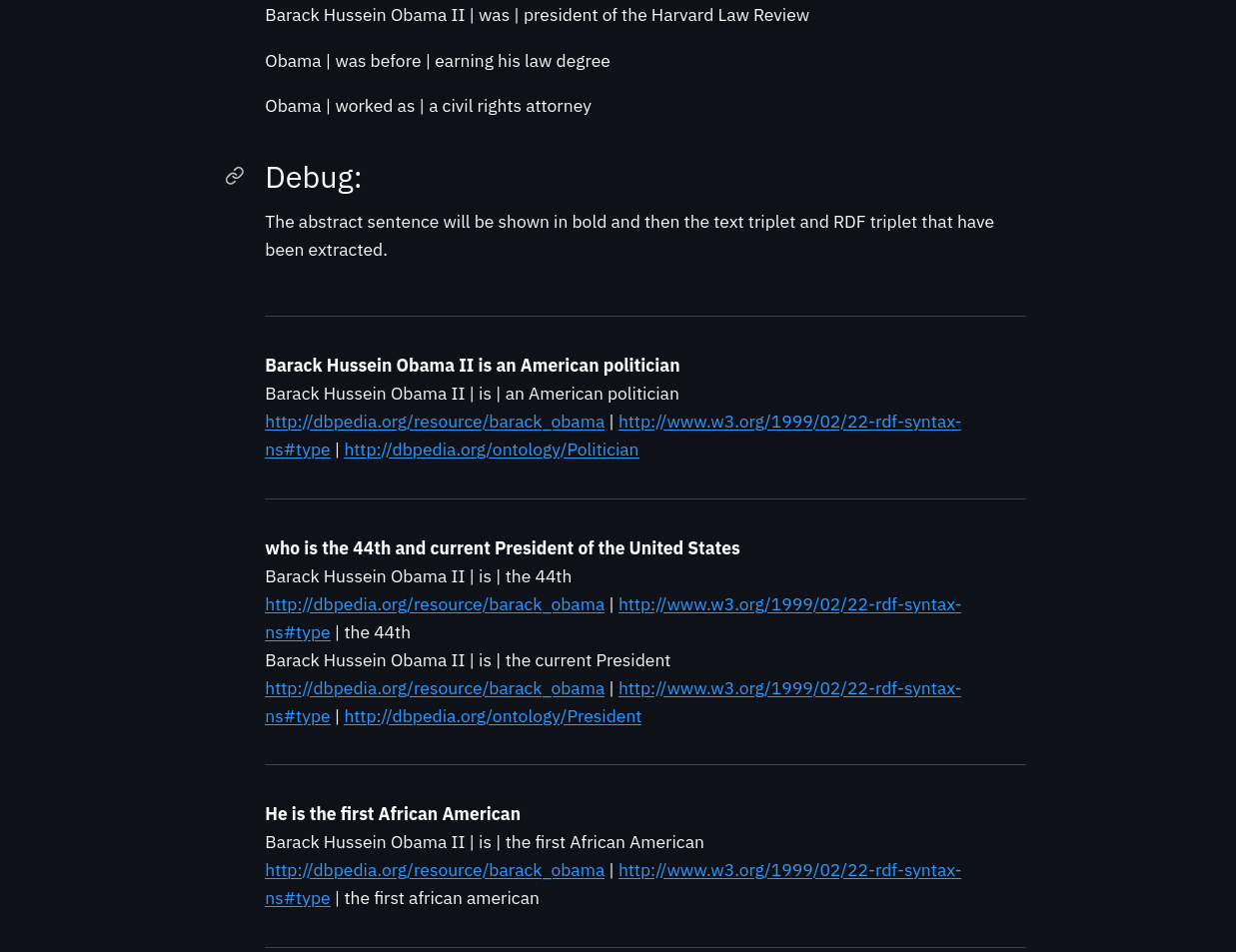
Once a user clicks on the submit button a link to download the generated ttl file is generated at the top of the outputs. Although I have insisted that this tool makes it very easy to build web pages, I have encountered many difficulties in generating a way to download the file. By default streamlit does not include any function for users to download files, so it had to be done manually. For more information about this problem see the following function
To run the web application just run the following command:
streamlit run code/webapp/app.py
Command line App
It is really the same as the web application but with a different type of interface. As with the web application, the user can specify certain arguments that modify the behavior of the program.
Calling the application without any arguments or with the --help argument results in the following output:
fcabla@fcabla-MS-7C56:~/Documents/GSoc/DBpedia-abstracts-to-RDF$ python3 code/app/app.py --help
usage: app.py [-h] --input_text INPUT_TEXT [--all_sentences] [--text_triples] [--no_literals] [--save_debug] [--save_debug]
Text to RDF parser
optional arguments:
-h, --help displays this help message and exits.
--input_text INPUT_TEXT
Insert abstract text or any other type to generate RDF based on the input
--all_sentences Use all sentences of the abstract or only the simplest sentences (False recommended)
--text_triples Print the simplified statements of the triples that have been generated. This is useful for understanding how the pipeline processed the input
--no_literals Discards all triples containing a literal. This occurs when the pipeline cannot find any lexicalization for the predicate or the object
--save_debug Prints the text triples and the extracted RDF triples for each sentence.
The arguments are identical to those of the web application except for the first one, which is mandatory for the application to work, which specifies the path to the file with the input file (DBpedia abstract or any text)
An example of the program execution would be the following:
python3 code/app/app.py --input_text="code/app/input.txt" --all_sentences --save_debug
Final evaluation period
Being this the last week, I have dedicated some time to generate documentation, test the application, prepare the github repository and evaluate both my mentor and DBpedia. During this evaluation I also had to give my opinion about certain aspects of Google Summer of Code as well as explain what I found the most difficult and the most enjoyable aspects of this journey.
Future work (what is left to do)
As this is the last week of development I thought it is a good idea to indicate to the users what will be the next steps in the development of this project.
The main problem of the pipeline right now is that of all the triples it can generate, only half of them are free of errors in their structure. This kind of errors occur when the pipeline is unable to find a valid lexicalization for the predicate (verb+preposition) or for the object, leaving these elements as Literals instead of as resources or properties. They are not really errors, they are more like non-capture patterns since the elements that failed during lexicalization are just not covered by the lookuptables.
When we mention lexicalization we refer to the translation of text to URIs using tables (json files). As already seen during blog post 9 the origin of most of these errors is when lexicalizing verbs and prepositions, since the current state of the lookup table does not cover the estimated number of cases.
Because of the above, the next step in the development of this tool would be to collaboratively add many more translations, so we will be able to cover many more cases and therefore generate more RDF triples.
Once many more lexicalizations are added we will be able to be stricter when generating RDF triples because at the moment there are also some errors associated with the content of the triple. This occurs when the range or domain of the RDF property does not match the classes of the resources in the subject and predicate. The reason for this error is again the fact that there are hardly any property lexicalizations at the moment.
Also the text processing part should be reworked, especially when dealing with more complex sentences. Complex sentences are those that have more than one verb and must be simplified before translating them into RDF.
Finally, it would also be nice to implement a system to always have the lexicalization tables updated, so that each time the application is run it checks if these tables are in the latest possible version.
Conclusions
In conclusion, during this week i have been able to build a web applications to allow the users to test the pipeline. In addition, I have generated more documentation, cleaned up the repository and performed the final evaluation.
This has been an amazing journey in which I have had the opportunity to learn many concepts in the area of natural language processing as well as gaining a lot of experience with the Python programming language. Also, this has been the first time that I have participated in an Open Source project and I really enjoyed the experience, I will certainly continue contributing to this kind of projects.
Finally I would like to thank both my tutor and the DBpedia organization for their help and for the opportunity to participate with them in this interesting project that has undoubtedly contributed to my personal enrichment.
Note: Although the project is formally finished (according to the schedule established by GSoc), I intend to tweak, add or improve some small details during this week.
For more information please check the repository or the folder containing the web app.