Analysis of the pipeline
During the ninth week we have been testing the performance of the application by testing it with 10000 DBpedia abstracts. With this we intend to obtain several metrics such as the number of simple sentences, complex sentences, number of lexicalization failures, etc. In addition, the local DBpedia spotlight server has been installed to use it instead of the online API.
DBpedia spotlight local installation
The first step was the installation of the DBpedia Spotlight local server. Until now we had been using only the online API, because it was more convenient to use the online API instead of deploying our own server.
The main reason for the decision to change is the difference in response time between the online API and the local server. As expected, the response time of the local server is much lower than the online service. In addition, the Spotlight API limits the number of requests from time to time, so it is not a good alternative for the tests to be done during this week. On the other hand, it is suspected that the model used in the online API is not the latest version.
The downside of opening the local server is that it occupies 8 Gb in RAM. Luckily I have a 32 Gb machine and it is not a problem, but it is still a large amount of memory.
The folder with the Spotlight server related files and a short guide on how to install it can be found here. Both the model and the server file are not on Github as they exceed the maximum allowed size, if you want to install it please read the file Readme.md.
General clean up of the Github repository
This week we have also taken the opportunity to clean up and organize the project structure in Github since we are close to the end of the project.
Now, in all the folders there is a readme file that indicates what each file does inside that folder. In addition, all the code has been moved to two folders: The scripts folder contains those files that have been used at some point in the execution of the project and that are not part of the main pipeline. The codingweeks folder contains one python file for each week with the formation cw+week number. These files constitute the main pipeline and have been made this way to be able to distinguish well the difference between the previous week and the current week.
In the last week a new folder with the web application will be created.
Statistics / Results
The idea of this section is to evaluate the performance of the proposed pipeline and identify in which cases the application fails and why.
The intended experiment is to run the pipeline developed so far with 10000 DBpedia abstracts, so that when we measure the metrics we can make sure that we are not evaluating any outlier.
Although the system has been fed with 10,000 abstracts, only 9938 have been used for this experiment since the remaining 62 inputs have produced an error when evaluated by DBpedia Spotlight. All averages referenced below are for the number of abstracts for which no error occurred (100% == 9938).
Number of sentences
The first metric to be evaluated is the number of simple and complex sentences we are able to extract from each abstract. Recall that so far simple sentences are those that consist of a single regular verb, an auxiliary verb or an auxiliary verb followed by a regular verb.
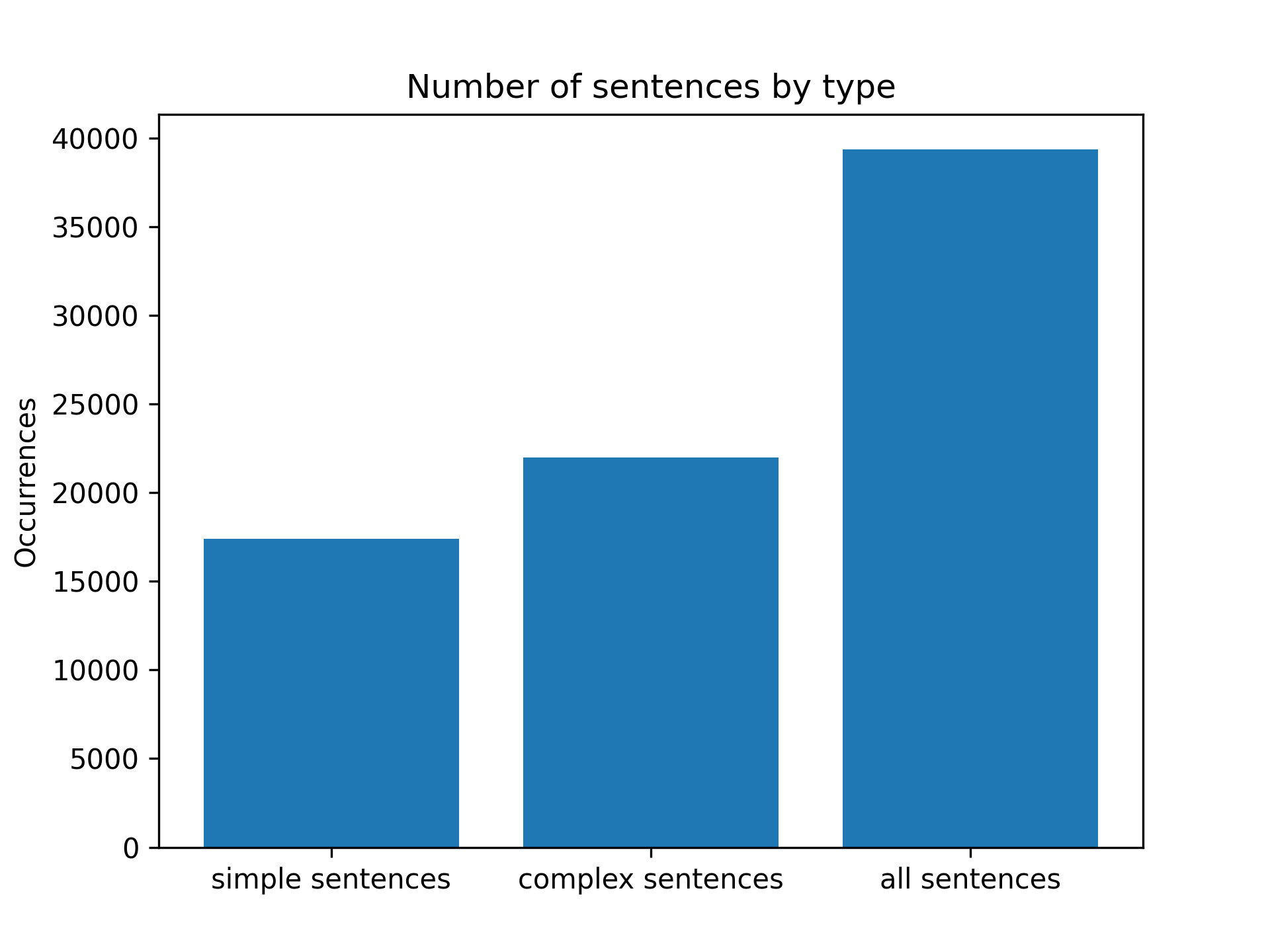
From the available abstracts, 17388 simple sentences and 21981 complex sentences have been obtained. For each abstract it is estimated that 1.75 simple sentences and 2.21 complex sentences are extracted.
Number of triples (text and RDF)
The next metric to be studied is the number of text triples and RDF triples generated from each sentence type. Before looking at the results it was expected that the number of Text triples would be higher than the number of RDF triples but this is not quite true.
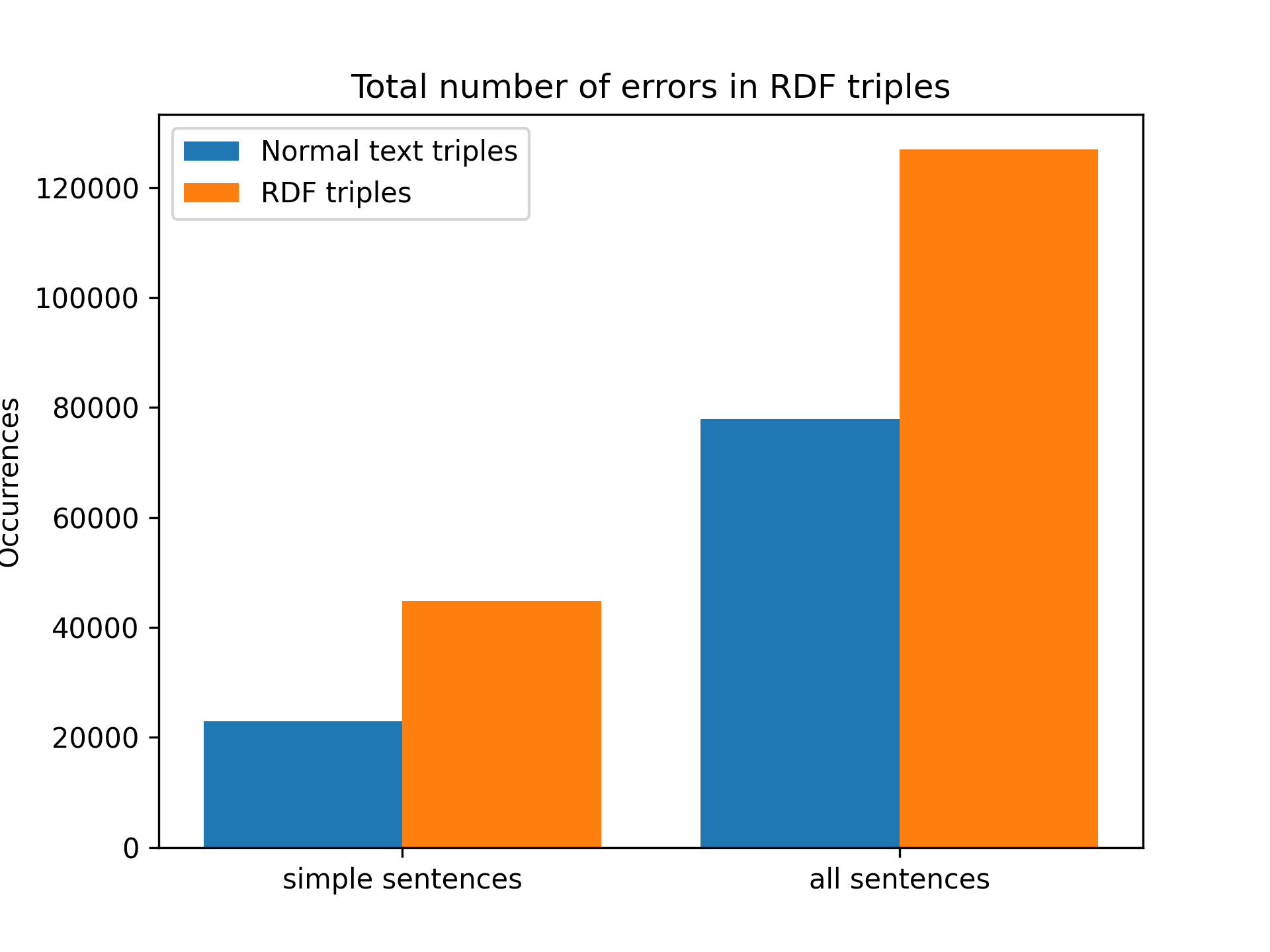
As can be seen in the graph, using only single sentences, 29524 text triples and 44778 RDF triples have been obtained. This means that for each processed abstract (simple sentences only) an average of 3 text triples and 4.5 RDF triples are obtained. If all sentences (simple + complex) are used, 77296 text triples and 127010 RDF triples are obtained. This means that for each processed abstract an average of 7.8 text triples and 12.8 RDF triples are obtained.
From these numbers you can see that about 1.5 RDF triples are generated for each text triple. Although we thought that the opposite would be true, this makes a lot of sense since one RDF triple is generated for each resource identified by Spotligh in a text triple object. This can mean two things, either we need to raise the confidence level of each Spotlight query so that fewer candidates are generated or we are doing a bad job of simplifying the sentences to generate the text triples.
Elements non-captured in predicate (lexicalization of verbs+prepositions)
Next we will check the number of errors (pattern not covered) generated during the abstract processing, starting with the failures to lexicalize verbs and prepositions. These errors occur when a triple contains a verb + preposition that is not in the lexicalization table. For more information about this lookuptable see blog post 7.
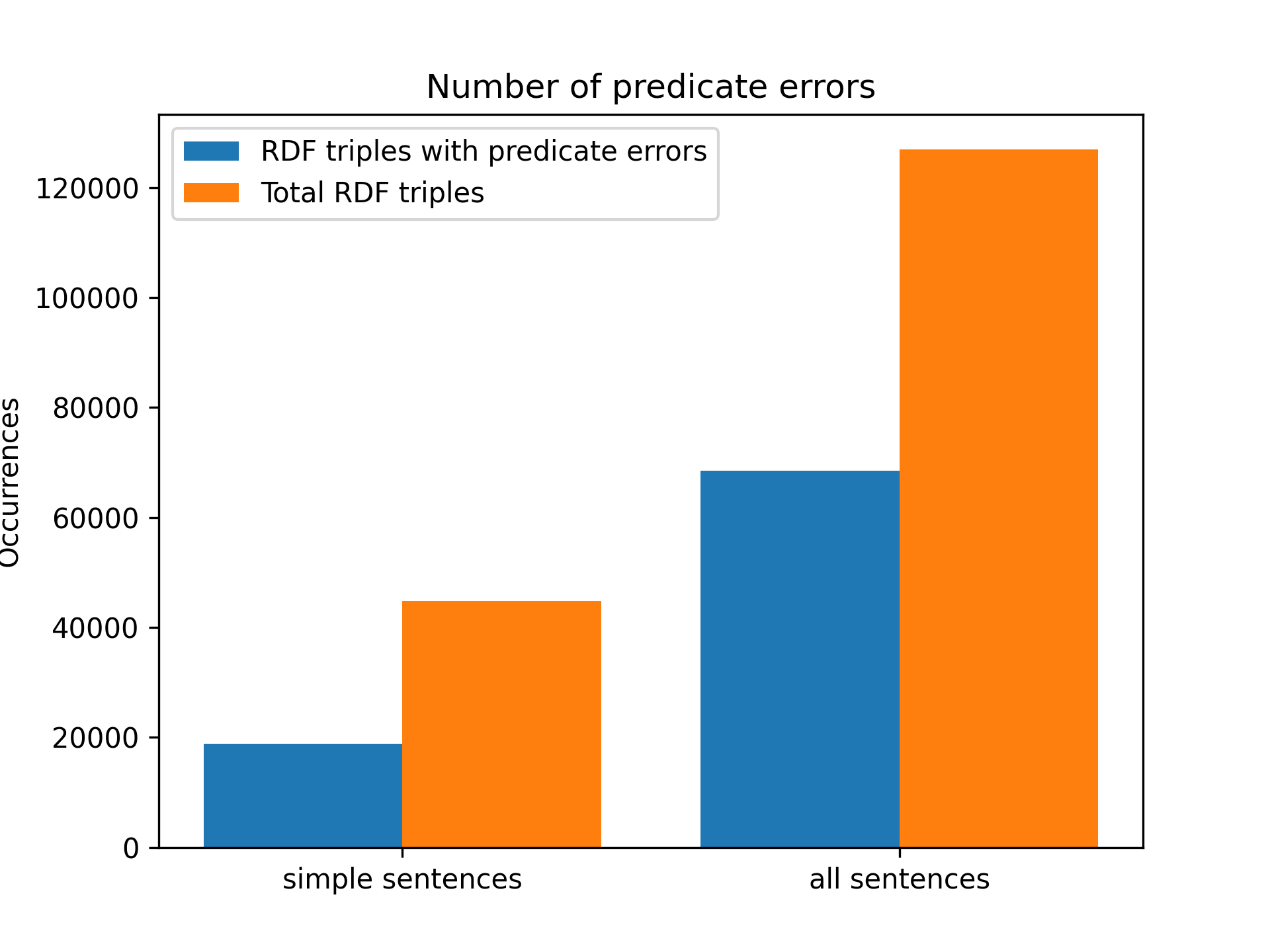
As can be seen in the graph above, 18871 errors occurred when processing only single sentences and 68529 errors occurred when processing all sentences. These errors represent 42% and 53% of the total number of triplets, which makes us think that the lexicalization table for verbs and prepositions is not covering the number of cases initially estimated, around 70%. We are currently covering between 50 and 60% of the cases.
To check this, we have re-plotted the 10 most common verbs (see blog post 7) to better observe how many cases we are able to cover.
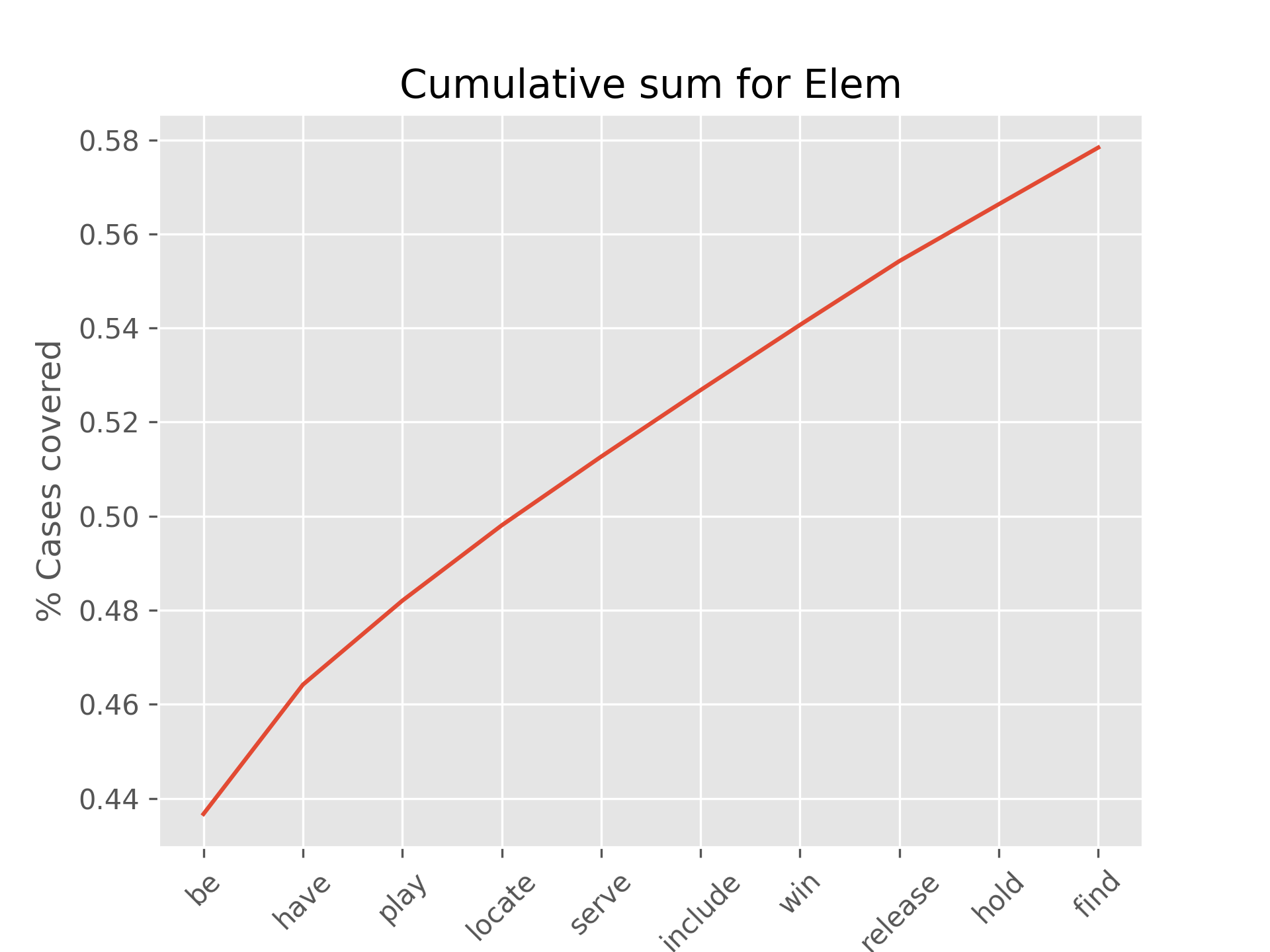
Total count = 17530
elem count cumsum
0 be 7655 0.436680
1 have 482 0.464176
2 play 313 0.482031
3 locate 281 0.498060
4 serve 256 0.512664
5 include 248 0.526811
6 win 243 0.540673
7 release 238 0.554250
8 hold 212 0.566343
9 find 211 0.578380
These last two outputs have been calculated to make sure of the large number of cases covered by the verb to be on its own.
Elements non-captured in objects when predicate is the verb to be (lexicalization of DBpedia classes)
Another type of error (pattern not covered) that can occur when generating RDF triples from text triples is when the verb of the triple is the verb to be. When this case occurs, the text triple object must be replaced by a DBpedia ontology class instead of a resource identified by Spotlight. Failures related to this case occur when no valid lexicalization (ontology class) is found in the text triplet object. For more information about this lookup table see blog post 8.
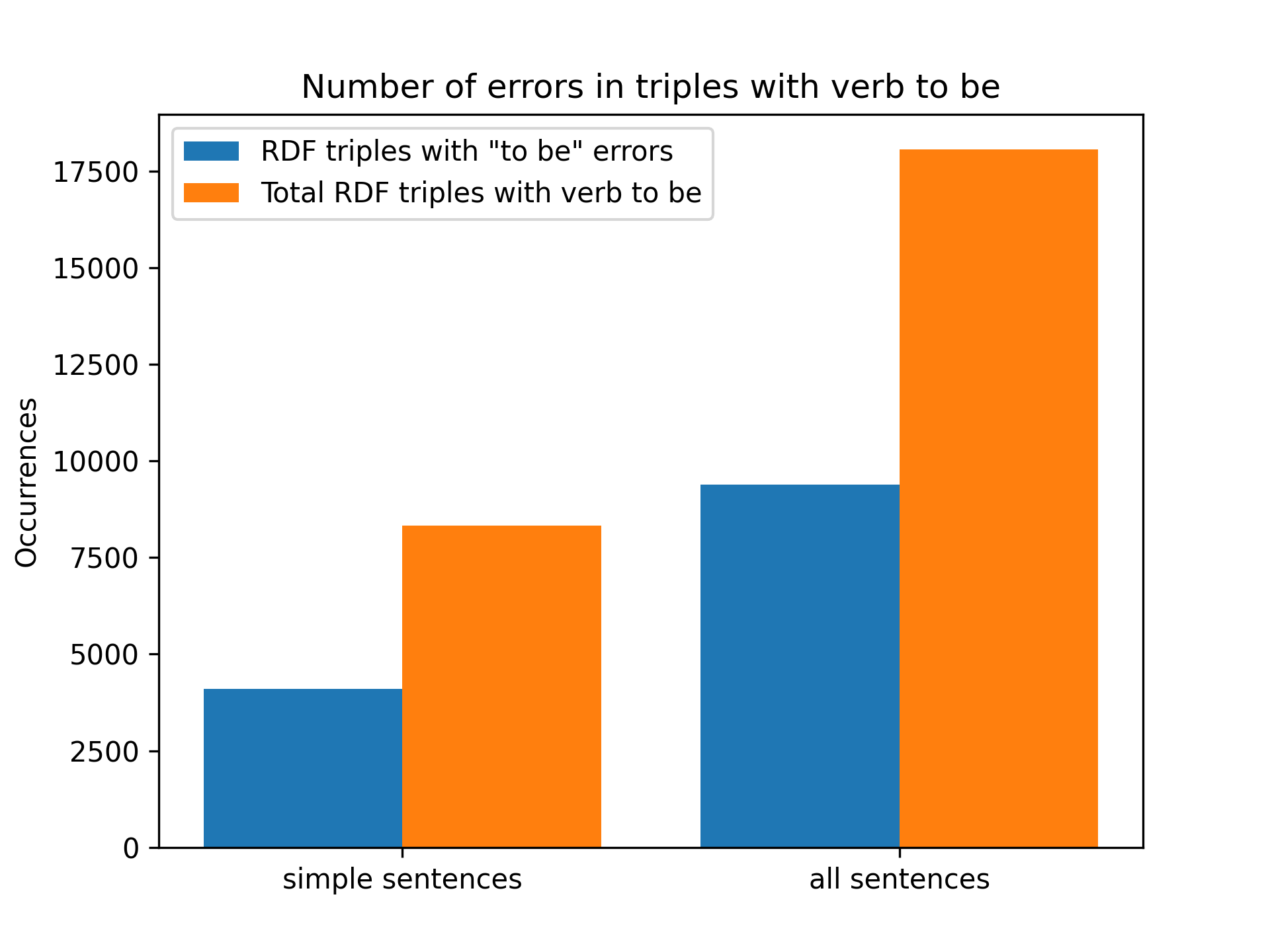
In the simple sentences 4105 errors have been committed for the 8323 triples containing the verb to be in the predicate. When processing all sentences (simple and complex) 9383 errors have been committed for the 18071 triplets containing the verb to be. In both cases the errors occur in about half of the triplets containing the verb to be in the predicate.
To try to reduce this number, a list of the triples in which this error has occurred has been generated in order to identify and add more cases to the table of lexicalization of classes of the DBpedia ontology. 83 new lexicalizations have been added to the lookup table (before 772 vs 855 now). This can be consulted here.
Total number of not covered patterns (any literals in triple)
The following graph shows the number of triples containing any of the two errors shown above vs the total number of RDF triples generated.

In the single sentences we find that about 51% of the triples are erroneous, while when processing all sentences the error rate increases to 61%.
Time to execute the experiments
The last metric to be discussed is the time it takes for the pipeline to execute. Dealing only with single sentences, the whole experiment took 4489.9 seconds (1.25 hours) while processing all sentences the experiment took 4725.96 seconds (3.72 hours). It has been calculated that each abstract takes 0.45 seconds just processing the single sentences and 0.475 seconds processing all the input sentences.
Discussion
In terms of the number of RDF triples generated correctly, we can state that approximately half of the results do not contain any literal, i.e. the triples follow the pattern resource | property | resource. On the contrary, we have been able to see that most of these errors occur because the verb is not registered in the lexicalization table. Apparently, with the verbs in the lexicalization table we are not covering the estimated number of cases, we are only able to cover about 55% of the cases instead of the estimated 70%.
The errors that have been commented so far are only in reference to the triple formation, however other errors related to the range and domain of the properties also occur. At the moment, the developed tool searches the lexicalization table for the property with a range and domain that is close to the classes of the subject and object resources. This means that even if the selected property may be a good translation from text to RDF it does not meet the class and domain constraints.
This is a question of how permissive we are in generating the triples. If we were stricter, the number of range and domain errors might disappear at the cost of generating far fewer triples. We have decided to be more flexible since the lexicalization table for verbs and prepositions does not contain a large number of alternative lexicalizations or properties for each combination.
To improve the pipeline we would have to add many additional lexicalizations to both lookup tables since our maximum accuracy is conditioned by the number of cases we are able to cover with the lookup tables. We should also consider if the parameters we are using in each Spotlight query are correct or should be fine tuned (confidence and support level) or if the parameters of . Finally, the simplification of the phrases should also be reviewed, since by optimally simplifying the phrases, Spotlight should only identify one resource (in the text triplet object).
Update (23/08/2021)
In order to better identify which verbs we are not covering in the verb+preposition lexicalization table we have generated a list of cases where the lexicalization has failed. This is very similar to what we did with the lexicalization errors of the DBpedia classes (errors with the verb to be).
This table of examples of errors can be consulted here.
Update (03/09/2021)
When a literal appears in the triplet, these are not really errors, but rather patterns that are not covered by the current lookuptables.
Conclusions
In conclusion, during this week we have been able to check the functioning of the pipeline developed so far as well as get an idea of what things are going wrong and how we could fix them.
In the next week we will focus on creating a web tool to build a small demo that can run in any browser. We will start by making this same application but for command line. Finally, if time permits, we will try to improve the pipeline either by introducing new lexicalizations or by identifying new patterns when processing text.
For more information please check the repository or the source file of this coding week 9.